🧪 RAG Evaluation Framework: A Practical Guide
As AI becomes embedded into every aspect of modern applications, evaluating AI-generated outputs is no longer optional—it's essential. In this post, we'll walk through how to set up a Retrieval-Augmented Generation (RAG) evaluation framework to detect hallucinations, monitor drift, and ensure factual consistency in your AI applications.
🚨 Designing an evaluation pipeline early avoids surprises in production when incorrect or hallucinated outputs can impact real users.
🎯 Why Build a RAG Evaluation Framework?
We're in a transformative era where AI is a first-class citizen in software architectures. RAG systems combine retrieval with generation—making evaluations more nuanced than simple text classification.
Establishing a robust evaluation framework helps:
- Measure performance using objective metrics
- Track factual correctness and hallucination rate
- Catch model drift over time
- Provide actionable insights for model tuning
🔍 Core Components of a RAG Evaluation System
To evaluate a RAG-based AI application, you typically need:
- Evaluator Model (LLM-as-a-Judge)
- Generator Model Output (LLM Response)
- Reference Ground Truth (Expected Answer)
- Context used by the model (retrieved documents)
📊 Evaluation Flow Overview

🧰 Using RAGAS for Evaluation
We’ll use the open-source RAGAS framework to demonstrate how to calculate meaningful RAG evaluation metrics.
✅ Key Metrics
Here are the metrics we’ll focus on:
- Context Precision: % of relevant chunks in retrieved context
- Context Recall: % of important chunks that were successfully retrieved
- Context Entity Recall: % of key entities recalled in the context
- Noise Sensitivity: Likelihood of incorrect responses from noisy input
- Response Relevance: How well the answer aligns with the user input
- Faithfulness: Is the response factually supported by the retrieved context?
⚙️ Setup Instructions
Install required packages:
pip install langchain-aws ragas
📘 Sample Dataset for Evaluation
We’ll use a simple geography Q&A dataset to show how RAGAS works:
GEOGRAPHY_QUESTIONS = [
"Where is the Eiffel Tower located?",
"What is the capital of Japan and what language do they speak?",
...
]
Each sample includes:
user_inputresponsefrom the AIreferenceground truthretrieved_contextsused by the model
# Example Entry
user_input = "Where is the Eiffel Tower located?"
response = "The Eiffel Tower is located in Paris, France."
reference = "The Eiffel Tower is located in Paris, the capital city of France."
retrieved_contexts = ["Paris is the capital of France. The Eiffel Tower is one of the most famous landmarks in Paris."]
📊 Evaluation Results
Once metrics are calculated using RAGAS, you’ll get a table like this:
| Question | Context Recall | Faithfulness | Factual Correctness |
|---|---|---|---|
| Where is the Eiffel Tower located? | 1.0 | 1.0 | 1.0 |
| What is the capital of Japan...? | 0.0 | 1.0 | 1.0 |
| Which country has Rome...? | 0.667 | 1.0 | 1.0 |
💾 Results saved to
geography_evaluation_results.csv
🧠 Optional: Other Evaluation Options
If you're already using AWS:
- Check out Amazon Bedrock's native RAG evaluations
- Integrate with Bedrock Knowledge Bases for end-to-end monitoring
Metrics Avaiable
The AWS Evaluation Service offers the following set of evaluation metrics.
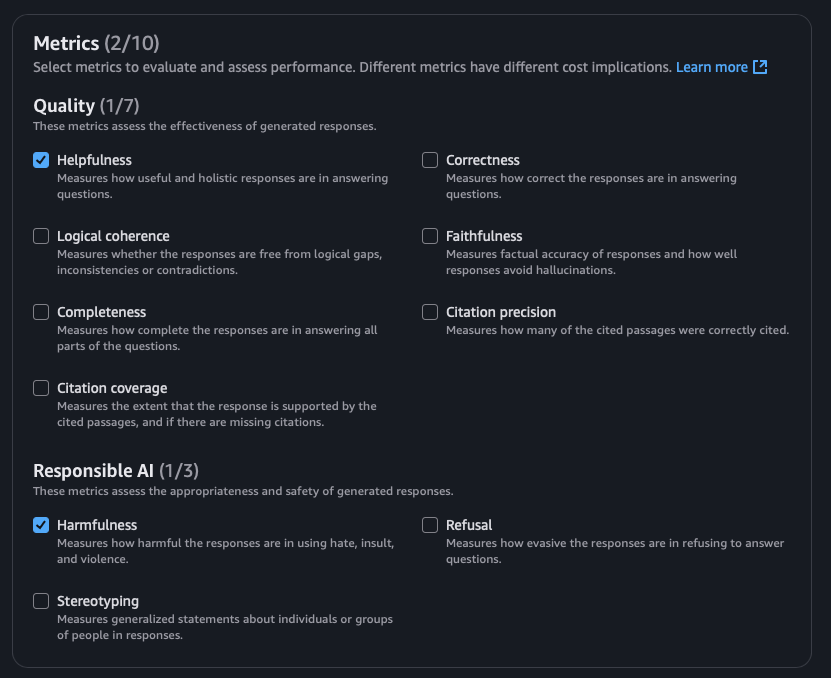
Screenshots from AWS Evalaution Job

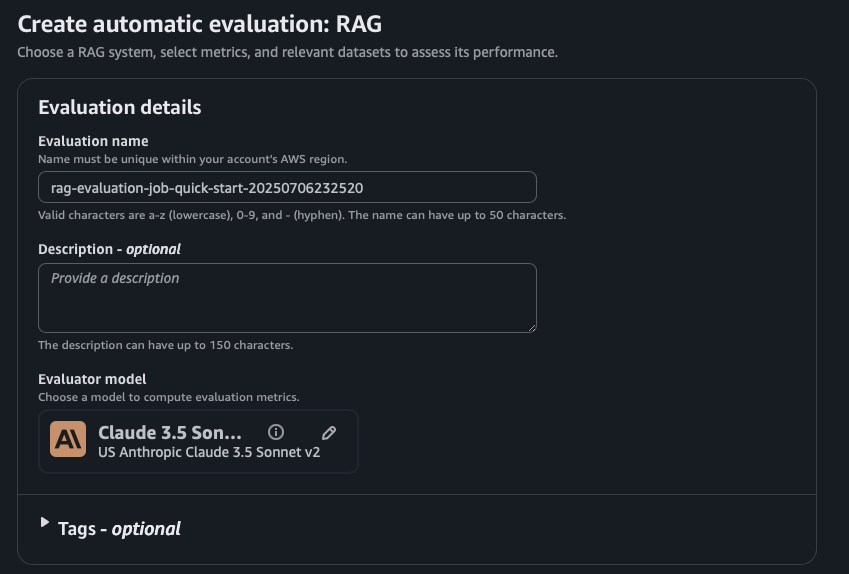
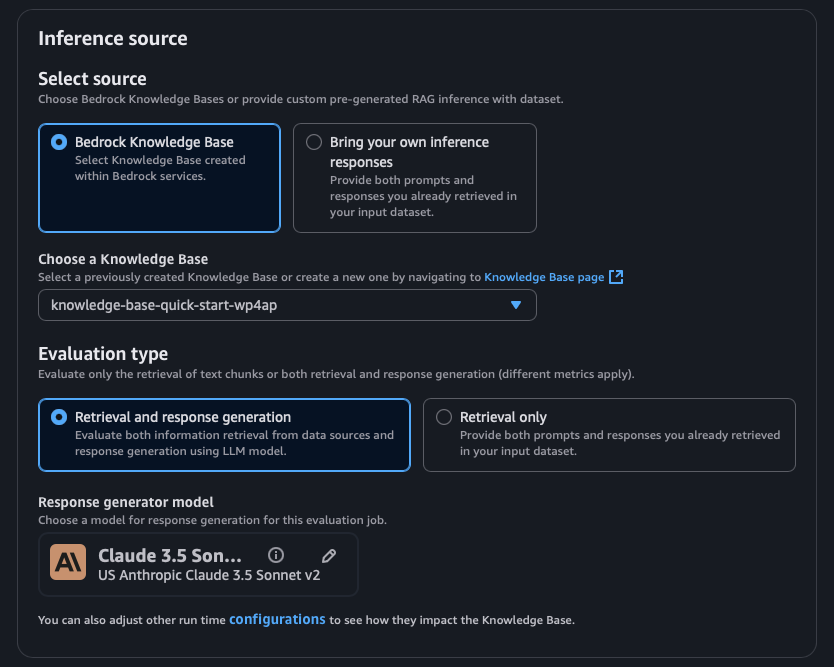
Sample Output from AWS Evaluation Job
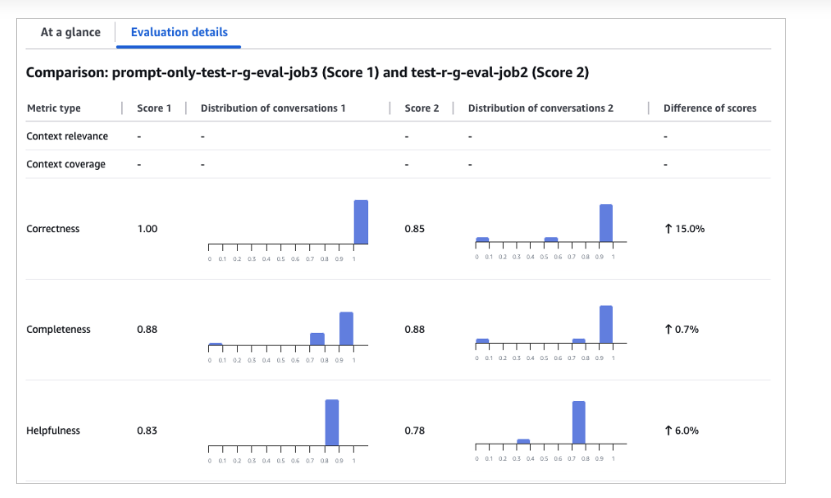
The Evaluation Job offers a user-friendly interface that presents various evaluation metrics in a clear, visual format—making it easy to review individual questions alongside their corresponding scores.
🔗 Resources
🚀 Wrapping Up
This guide offers a foundational setup to get started with evaluating RAG pipelines. Whether you're validating hallucinations, tuning retrieval logic, or comparing generator outputs—RAGAS makes it easy to measure what matters.
Happy building & stay responsible with your AI systems! 🛠️