🛡️ Building Responsible AI Apps with AWS Guardrails
In the world of Retrieval-Augmented Generation (RAG), context validation and content safety are non-negotiable—especially when your app is dealing with sensitive or regulated information.
In this post, we'll explore how to use AWS Guardrails, a fully managed service in Amazon Bedrock, to validate prompts and responses in RAG applications and enforce responsible AI policies at scale.
👉 AWS Guardrails Official Docs
🤖 Why Guardrails Matter in RAG Applications
When building LLM apps—especially RAG-based ones—you need strong controls over:
- ❌ Prompt Injection risks
- 🧠 Hallucinated responses from foundation models
- ⚠️ Unsafe content, including harmful or biased language
- 🔒 Sensitive data exposure (like PII)
AWS Guardrails acts as a contextual safety layer between user inputs and model outputs, helping you monitor, block, or redact unsafe, off-topic, or ungrounded interactions — in both prompts and responses.
🧩 Guardrails Capabilities Overview
Guardrails is fully configurable with granular policies for:
| Policy Type | Purpose |
|---|---|
topicPolicyConfig | Block specific subject areas (e.g., investment advice) |
contentPolicyConfig | Detect and moderate harmful content (e.g., hate, violence, misconduct) |
wordPolicyConfig | Flag or block specific keywords or phrases |
sensitiveInformationPolicyConfig | Anonymize or block PII and sensitive data |
contextualGroundingPolicyConfig | Set thresholds for relevance and factual grounding |
blockedInputMessaging | Define fallback messages for blocked prompts |
blockedOutputsMessaging | Define fallback messages for blocked responses |
📐 Architecture with Guardrails
Here’s a simplified architecture of a RAG chatbot using AWS Bedrock + Guardrails:

🛠️ Sample Guardrails Configuration (Python Snippet)
description = "Prevents our model from providing proprietary information."
topicPolicyConfig = {
"topicsConfig": [
{
"name": "AI Social Journal Denied Topics",
"definition": "Personalized financial recommendations or fiduciary advice.",
"examples": [
"What stocks should I invest in?",
"How should I allocate my 401(k)?",
],
"type": "DENY"
}
]
}
contentPolicyConfig = {
"filtersConfig": [
{"type": "SEXUAL", "inputStrength": "HIGH", "outputStrength": "HIGH"},
{"type": "VIOLENCE", "inputStrength": "HIGH", "outputStrength": "HIGH"},
{"type": "HATE", "inputStrength": "HIGH", "outputStrength": "HIGH"},
{"type": "INSULTS", "inputStrength": "HIGH", "outputStrength": "HIGH"},
{"type": "MISCONDUCT", "inputStrength": "HIGH", "outputStrength": "HIGH"},
{"type": "PROMPT_ATTACK", "inputStrength": "HIGH", "outputStrength": "NONE"},
]
}
wordPolicyConfig = {
"wordsConfig": [
{"text": "financial planning guidance"},
{"text": "retirement fund suggestions"},
{"text": "trust fund setup"},
],
"managedWordListsConfig": [{"type": "PROFANITY"}],
}
sensitiveInformationPolicyConfig = {
"piiEntitiesConfig": [
{"type": "EMAIL", "action": "ANONYMIZE"},
{"type": "NAME", "action": "ANONYMIZE"},
{"type": "US_SOCIAL_SECURITY_NUMBER", "action": "BLOCK"},
],
"regexesConfig": [
{
"name": "Account Number",
"description": "Matches 10-digit account numbers",
"pattern": r"\b\d{6}\d{4}\b",
"action": "ANONYMIZE"
}
]
}
contextualGroundingPolicyConfig = {
"filtersConfig": [
{"type": "GROUNDING", "threshold": 0.75},
{"type": "RELEVANCE", "threshold": 0.75}
]
}
blockedInputMessaging = "Sorry, I can't assist with that."
blockedOutputsMessaging = "Sorry, I can't assist with that."
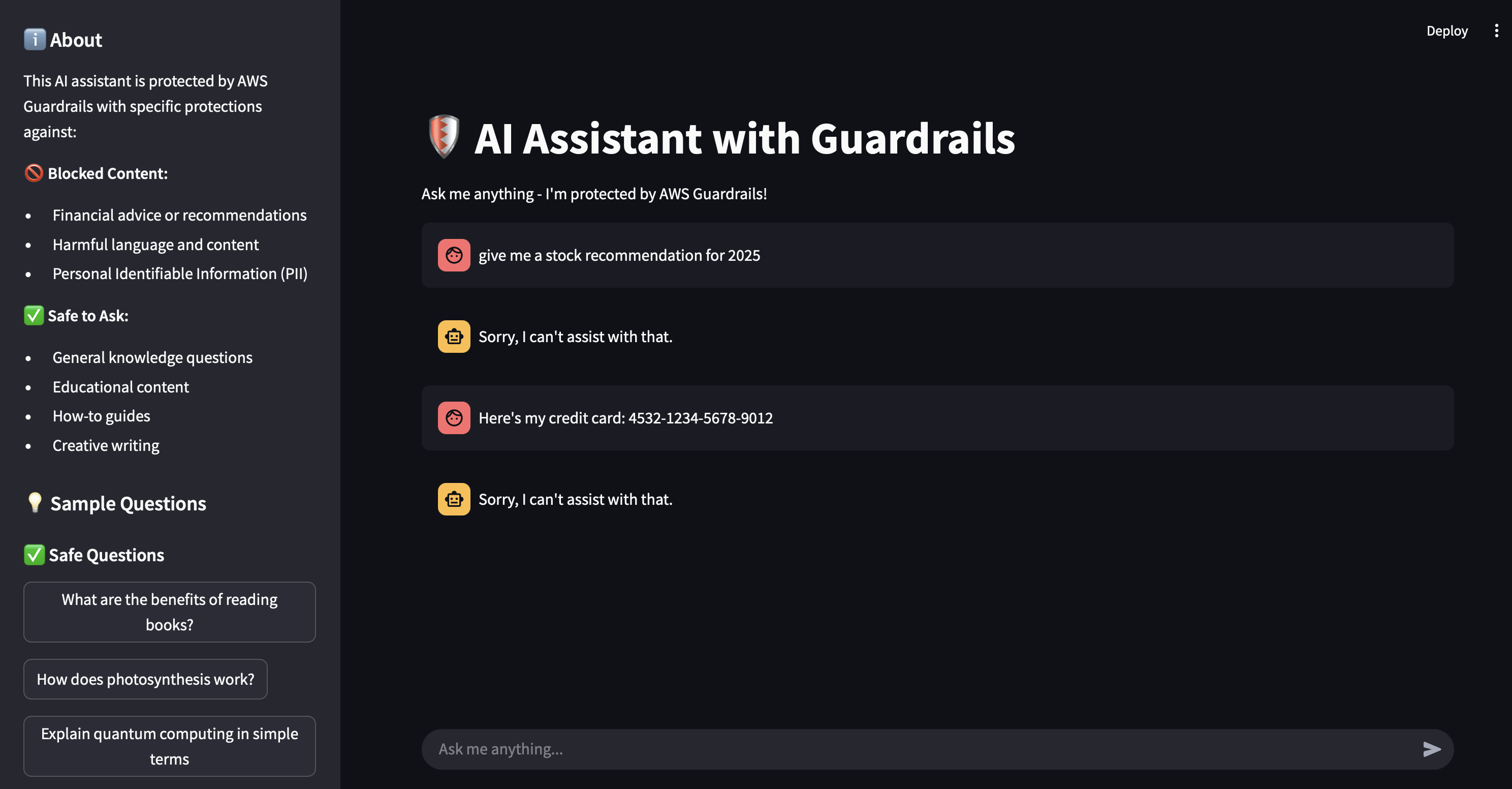
🚀 Live Demo with Streamlit
To demonstrate this setup, I built a Streamlit app that validates both user input and model responses using AWS Guardrails. The app lets you:
- Ask questions via a chat interface
- Watch Guardrails intercept unsafe prompts or outputs
🧪 Response from Guardrails
Here’s how the app behaves:
- User prompt violates topic policy → receives fallback message
- Model hallucination exceeds relevance threshold → blocked
- PII detected in user prompt → redacted automatically
✅ Safety, groundedness, and compliance—by design.
📁 Full Codebase
You can find the complete working example and integration code on GitHub:
🔗 View on GitHub
🧭 Final Thoughts
If you’re building production-grade RAG or chatbot applications, AWS Guardrails should be part of your stack from day one.
It helps you:
- Catch unsafe prompts before they reach the LLM
- Block hallucinated or off-topic answers
- Protect sensitive information
- Build trust in your AI systems
And best of all — it’s configurable, scalable, and fully managed.