🔍 Building a RAG Application with AWS Knowledgebase
In our previous post, we walked through the essential building blocks of a Retrieval-Augmented Generation (RAG) application:
- Data preparation
- Chunking strategy
- Embedding generation
- Vector database storage
- Retrieval of relevant context
- Augmentation of LLM prompts
- Response generation
What if I told you that all of these steps can now be abstracted into a fully managed service—and spun up in minutes?
🚀 Enter AWS Knowledge Bases.
⚙️ What is AWS Knowledgebase?
AWS Knowledgebase in Amazon Bedrock is a fully managed RAG orchestration service that lets you:
- Ingest and chunk your data
- Generate embeddings
- Store embeddings in a vector store
- Retrieve relevant content
- Feed it into an LLM (like Claude 4 or Cohere)
- Get a grounded response — via a single API
✅ Key Benefits
- Serverless setup
- Managed embeddings (pick from built-in options)
- Support for major vector DBs: OpenSearch Serverless, Weaviate, pgVector
- Built-in sync and refresh support
- Instant testing UI
In short: it abstracts away the entire RAG backend so you can focus on building the front-end experience and domain logic.
🛠️ Services Required
To get started, you’ll need:
| AWS Service | Purpose |
|---|---|
| S3 | To store your source documents |
| AWS Bedrock | To access foundation models like Claude |
| AWS Knowledgebase | The main service to manage RAG workflow |
| OpenSearch Serverless | Vector storage for embeddings |
| IAM | Permissions and policies for access |
Make sure your IAM user has permissions for all of the above.
💡 Setting Up Your Knowledgebase
You can create a Knowledgebase via:
- The AWS Console
- Or using the AWS CLI / SDK
During setup, you’ll:
- Upload PDFs or documents to S3
- Define chunking and embedding strategies
- Choose your vector DB (Used OpenSearch Serverless)
- Pick your LLM from Bedrock (e.g., Claude 3.5 Sonnet v2)
- Deploy and test right from the console
📌 Tip: Keeping your vector index synced is one of the most overlooked—but critical—steps in building production-scale RAG systems. AWS Knowledge Bases makes this a one-click action.
🧪 Quick Test Before Integration
Once your Knowledge Base is live, AWS lets you test it from the console to verify:
- Documents were chunked correctly
- Embeddings are being retrieved
- The LLM is producing grounded answers
Before writing a single line of code, you can simulate a real RAG interaction.
💬 Building a RAG Chatbot with Streamlit
To demonstrate this, I built a quick chatbot UI using Python and Streamlit. It connects to the retrieve_and_generate() API from the Bedrock Agent Runtime and leverages our Knowledge Base to answer questions from a PDF on AI in the enterprise.
🔧 Technical Implementation Details
The chatbot uses the following architecture:
- Frontend: Streamlit for the UI
- Backend: AWS Bedrock Agent Runtime API
- Model: Claude 3.5 Sonnet v2
- Vector Store: OpenSearch Serverless
- Document Source: S3 bucket with enterprise AI PDFs

Fig 1: RAG Architecture with AWS Knowledge Base
The codebase is organized into three key components:
- System Prompt: Provides instructions to guide the bot’s behavior
- API Integration: Connects to AWS Bedrock to retrieve the relevant document chunks
- Response Generation: Uses the retrieved context to craft accurate, grounded answers
🧠 Code Snippets
🔸 System Prompt Template
# Default knowledge base prompt
default_prompt = """
Act as a question-answering agent for the AI Social Journal Q&A Bot to help users with their questions.
Your role is to:
- Provide accurate information based on the knowledge base
- Be helpful, friendly, and professional
- If information is not available, suggest alternative resources or clarify the question
Guidelines:
1. Answering Questions:
- Answer the user's question strictly based on search results
- Correct any grammatical or typographical errors in the user's question
- If search results don't contain relevant information, state: "I could not find an exact answer to your question. Could you please provide more information or rephrase your question?"
2. Validating Information:
- Double-check search results to validate any assertions
3. Clarification:
- Ask follow-up questions to clarify if the user doesn't provide enough information
Here are the search results in numbered order:
$search_results$
$output_format_instructions$
"""
🔸 AWS Bedrock API Call
response = self.bedrock_agent_runtime_client.retrieve_and_generate(
input={"text": query},
retrieveAndGenerateConfiguration={
"type": "KNOWLEDGE_BASE",
"knowledgeBaseConfiguration": {
"knowledgeBaseId": os.getenv("KB_ID"),
"modelArn": os.getenv("FM_ARN"),
"retrievalConfiguration": {
"vectorSearchConfiguration": {}
},
"generationConfiguration": {
"promptTemplate": {"textPromptTemplate": default_prompt},
"inferenceConfig": {
"textInferenceConfig": {
"maxTokens": 2000,
"temperature": 0.7,
"topP": 0.9,
}
},
},
},
},
)
🎯 Chatbot Application Demo
To simulate the chatbot experience, I created a quick Streamlit application that showcases real RAG interactions:
 Fig 2: AI Social Journal Chatbot App
Fig 2: AI Social Journal Chatbot App
Example Document:
I used the OpenAI “AI in the Enterprise” document, which discusses the adoption of AI in large organizations, including its benefits and challenges.
📄 openai-ai-in-the-enterprise.pdf AI in Enterprise
Sample Prompt
“What are the key considerations for adopting AI in large organizations?”
🧠 Claude 3.5 retrieved the correct chunk from the Knowledge Base and provided a concise, contextualized answer — just like a smart analyst would.
📸 Sample Output
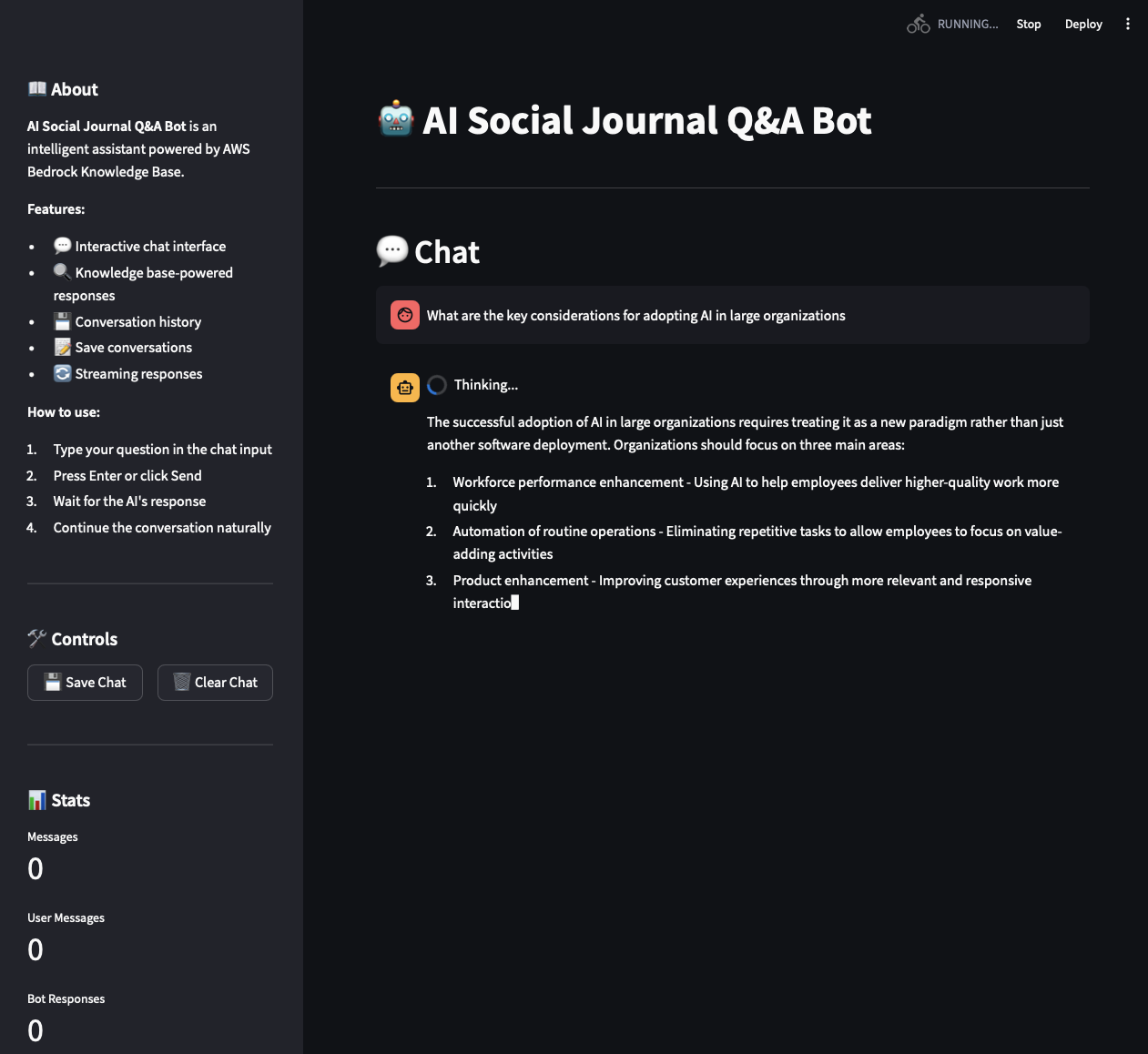 Fig 3: RAG Response Generation - Contextual AI Answer
Fig 3: RAG Response Generation - Contextual AI Answer
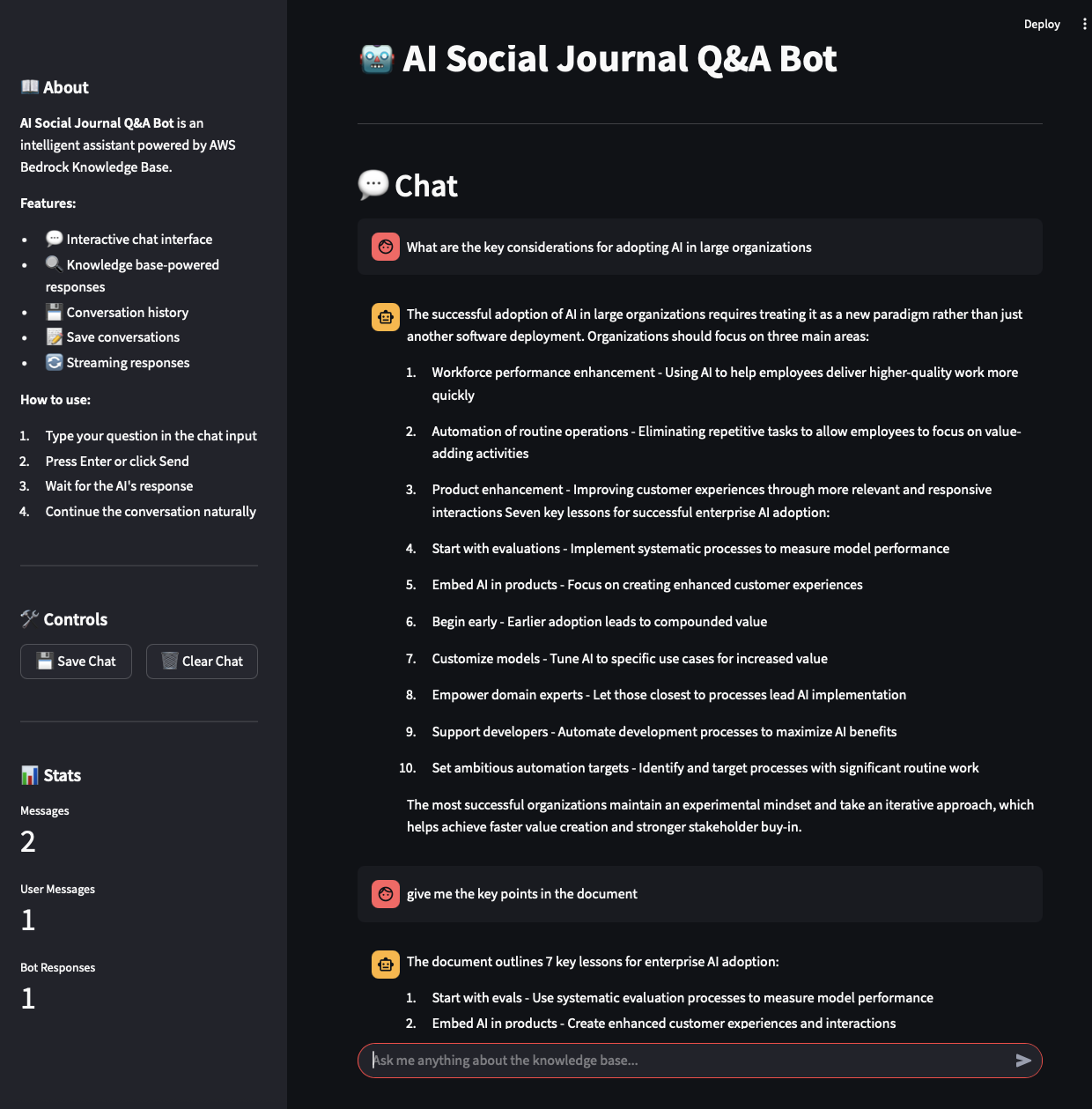 Fig 4: Conversation Flow - Multi-turn RAG Interactions
Fig 4: Conversation Flow - Multi-turn RAG Interactions
💰 Cost Considerations & Best Practices
AWS Knowledge Bases and its supporting services are not part of the free tier. Key cost factors:
- OpenSearch Serverless: Vector storage and search operations
- Amazon Bedrock: Model inference costs (pay-per-token)
- S3: Document storage (minimal cost)
- Data ingestion: Processing and embedding generation
🛡️ Cost Optimization Tips:
- Clean up resources when not in use
- Use CloudFormation templates or Infrastructure as Code (IaC) for easy provisioning/de-provisioning
- Monitor usage with CloudWatch and set up billing alerts
- Consider development vs production resource sizing
I created everything manually for this demo, but I strongly recommend automating deployment as a CloudFormation stack for easier cleanup and repeatability.
🧭 Final Thoughts
AWS Knowledge Bases simplifies the RAG development workflow dramatically:
- No need to manage chunking, embeddings, or retrieval logic
- Direct integration with Bedrock and serverless vector stores
- API or console-based orchestration
If you're building AI copilots, knowledge agents, or internal AI search tools — this is a game-changer for cutting down time-to-market and focusing on your app’s UX and logic.